Benieuwd welke soorten AI er zijn en welke het best past bij jouw doel? Je ontdekt het verschil tussen smalle, algemene en superintelligentie, hoe AI werkt (van symbolisch en deep learning tot neuro-symbolisch), en wat je ermee kunt doen, van generatieve content tot aanbevelingen, voorspellen en robotica. Met praktische tips over data, uitlegbaarheid, risico’s, kosten en trends zoals multimodaal, edge, kleine taalmodellen en RAG maak je snel een verstandige keuze.

Welke soorten AI zijn er op basis van capaciteiten
Als je naar soorten AI kijkt op basis van capaciteiten, draait het om hoe breed en diep een systeem kan denken en handelen, los van hoe het technisch werkt. Aan de basis staat smalle AI, ook wel ANI (Artificial Narrow Intelligence): systemen die één specifieke taak uitstekend uitvoeren, zoals spamfiltering, aanbevelingen in je streamingapp, fraudedetectie of beeldherkenning. Ze blinken uit binnen hun afgebakende domein, maar begrijpen niks buiten die context en kunnen hun kennis niet zomaar overdragen. Een stap hoger ligt algemene AI, AGI (Artificial General Intelligence): een hypothetische vorm die, net als jij, flexibel kan leren, redeneren, plannen en kennis toepassen over verschillende domeinen. Denk aan een systeem dat van een handleiding leert, vervolgens zelf een strategie uitwerkt en die aanpast als omstandigheden veranderen.
Dit bestaat vandaag niet, al laten grote taalmodellen en multimodale systemen wel zien hoe snel de lat verschuift. Bovenaan staat superintelligente AI, ASI (Artificial Superintelligence): een veronderstelde vorm die mensen op vrijwel alle cognitieve taken voorbijstreeft, van creatief probleemoplossen tot wetenschappelijke doorbraken; dat is toekomstmuziek met grote kansen én risico’s. Het onderscheid op basis van capaciteiten helpt je realistisch te blijven: wat je nu in de praktijk gebruikt is bijna altijd smalle AI, hoe indrukwekkend het ook lijkt. Of je nu een chatbot inzet, een voorspellend model bouwt of beelden analyseert, je werkt met gespecialiseerde systemen die je zorgvuldig moet trainen, begrenzen en evalueren op prestaties, betrouwbaarheid en veiligheid.
Smalle AI (ANI): gespecialiseerd in één taak
Smalle AI draait om systemen die één duidelijke taak heel goed uitvoeren binnen een afgebakende context. Denk aan spamfilters, aanbevelingen in je webshop, spraak-naar-tekst, gezichtsherkenning of een model dat medische beelden classificeert. Deze AI leert van trainingsdata en optimaliseert voor één doel, zoals nauwkeurigheid, snelheid of kosten, maar kan kennis niet makkelijk overdragen naar andere taken. Buiten de bekende data presteert het vaak slechter door data- of conceptdrift, dus je moet monitoren, hertrainen en duidelijke grenzen instellen.
Soms kun je met transfer learning een model fijnslijpen voor een verwante taak, maar het blijft smal. Let op bias in je data, definieer heldere evaluatiemetrics en bouw veiligheidsmaatregelen in. Als je precies weet wat je wilt automatiseren, is smalle AI meestal de snelste en betrouwbaarste keuze.
Algemene AI (AGI): brede, mensachtige intelligentie (toekomstig)
AGI verwijst naar systemen die net als jij flexibel kunnen leren, redeneren en plannen over uiteenlopende domeinen, zonder voor elke nieuwe taak opnieuw te worden geprogrammeerd. Zo’n systeem zou context begrijpen, causale verbanden doorzien, doelen kunnen bijstellen en kennis creatief hergebruiken, met geheugen en zelfreflectie om eigen fouten te corrigeren. Ondanks snelle vooruitgang met grote taalmodellen is AGI nog niet gerealiseerd; huidige modellen missen robuuste wereldkennis, consistent begrip van oorzaak en gevolg en betrouwbare autonomie.
Onderzoekers discussiëren over hoe je AGI zou meten, want simpele tests of losse benchmarks zeggen weinig over echte algemene intelligentie. Voor jou betekent dit dat je vandaag vooral met smalle AI werkt. Je kunt wel vooruit plannen door te investeren in uitlegbaarheid, veiligheid en governance, zodat je klaar bent voor meer generieke systemen.
Superintelligente AI (ASI): systemen die mensen in alles overtreffen (hypothese)
ASI verwijst naar een veronderstelde vorm van AI die mensen op vrijwel alle cognitieve taken voorbijstreeft, van wetenschappelijke ontdekking tot strategie, creativiteit en manipulatiebestendigheid. Zo’n systeem zou sneller leren, nauwkeuriger redeneren en zichzelf mogelijk verbeteren via iteratieve optimalisatie, wat een versnellend effect kan hebben. Het blijft speculatief: er is geen bewijs dat ASI nabij is, en we weten niet welke architectuur of meetlat daarbij hoort.
Toch is het relevant voor jou, omdat het de lat voor veiligheid en governance bepaalt. Denk aan het alignementprobleem: hoe zorg je dat doelen van een zeer capabel systeem blijvend sporen met jouw intenties? Praktisch betekent dit nu al inzetten op risicobeoordeling, robuustheid, interpretatie, mens-in-de-lus en duidelijke escalatiemechanismen, zodat je later niet achter de feiten aanloopt.
[TIP] Tip: Gebruik nu ANI; AGI/ASI zijn nog niet beschikbaar.
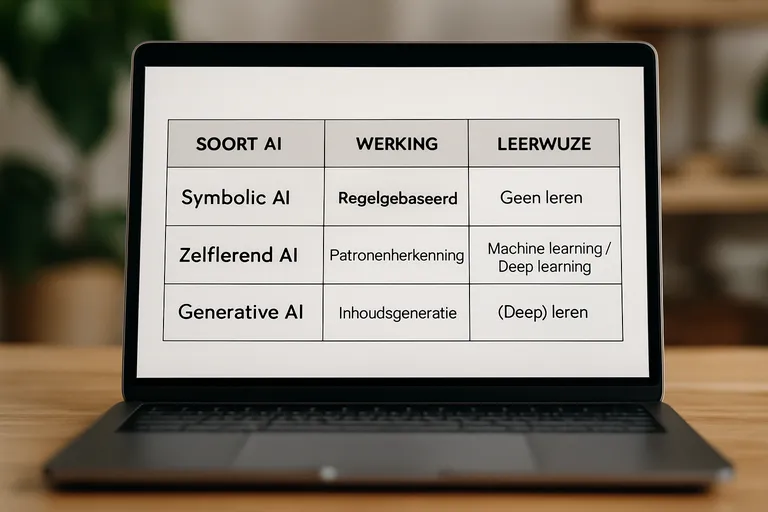
Vormen van AI op basis van werking en leerwijze
De tabel vergelijkt de belangrijkste AI-vormen op basis van werking en leerwijze, zodat je snel ziet wanneer je regels, (deep) leren of een combinatie inzet. Dit helpt bij het kiezen van de juiste aanpak voor je data, risico’s en doelen.
| Vorm | Hoe werkt het (kort) | Waar goed in | Voordelen & beperkingen |
|---|---|---|---|
| Symbolische AI (regels/kennis) | Expliciete if-then-regels, logica en ontologieën; deterministisch redeneren. | Compliance/beleid, productconfiguratie, regelgebaseerde triage, planning/constraint solving. | + Sterk uitlegbaar, weinig data nodig; – Zwak bij ruis/ambiguïteit, onderhoud intensief. |
| Neuro-symbolische AI | Combineert neurale netwerken met regels/kennisgrafen; leren onder constraints. | Document- & beeldbegrip met domeinkennis, kennisintensieve QA, consistentiecontroles. | + Prestaties én uitlegbaarheid; – Complex ontwerp, tooling/maturiteit wisselt. |
| Supervised learning (incl. deep learning) | Leert van gelabelde voorbeelden; o.a. beslisbomen, SVM, neurale netwerken (CNN/Transformer). | Classificatie, regressie, objectdetectie, spraak/vertaling, fraude- en vraagvoorspelling. | + Hoge nauwkeurigheid met voldoende labels; – Labelkosten, biasrisico, minder uitlegbaar (deep). |
| Unsupervised learning | Zoekt patronen zonder labels; clustering, dimensionality reduction, topic modeling, autoencoders. | Klantsegmentatie, anomaly detection, feature learning, data-compressie/visualisatie. | + Geen annotatie nodig; – Moeilijk te evalueren, gevoelig voor parameterkeuzes. |
| Reinforcement learning (incl. deep RL) | Agent leert via beloningen in (gesimuleerde) omgeving; policy/value optimalisatie. | Robotica & controle, sequentiële aanbevelingen, dynamic pricing/bidding, resource allocatie. | + Sterk voor beslissingen in stappen; – Veel interactie/simulatie, instabiel en veiligheidsrisico’s. |
Belangrijkste inzicht: kies symbolisch/neuro-symbolisch voor controle en uitleg; supervised voor prestaties met labels; unsupervised voor structuur zonder labels; RL voor stapsgewijze beslissingen. Combineren kan betrouwbaarheid en performance balanceren.
Als je naar vormen van AI kijkt op basis van werking en leerwijze, draait het om hoe een systeem tot beslissingen komt. Aan de ene kant heb je symbolische AI: regelgebaseerde systemen die expliciete kennisregels volgen en daardoor goed uitlegbaar zijn, maar minder robuust bij ruis of uitzonderingen. Aan de andere kant staat datagedreven AI, oftewel machine learning. Bij supervised learning leert een model van gelabelde voorbeelden; bij unsupervised learning ontdekt het patronen in ongetagde data; reinforcement learning leert via beloningen wat een goede actie is. Deep learning, met neurale netwerken, blinkt uit in complexe patronen zoals beeld, spraak en tekst, maar vraagt veel data en rekenkracht.
Steeds vaker zie je zelfgestuurde voortraining op grote datasets, waarna je een zogenoemd foundation model snel kunt fijnslijpen voor jouw taak. Hybride of neuro-symbolische AI combineert regels en leren, zodat je profiteert van zowel logische controle als datagedreven flexibiliteit. Welke vorm je kiest binnen deze soorten AI hangt af van je data, de vereiste nauwkeurigheid, uitlegbaarheid, kosten en snelheid, zodat de oplossing echt past bij je doel.
Symbolische en neuro-symbolische AI: regels combineren met leren
Symbolische AI werkt met expliciete regels, kennisgrafen en ontologieën, waardoor beslissingen uitlegbaar, herleidbaar en goed te auditen zijn, maar het kan stroef worden bij ruis of onvolledige data. Neuro-symbolische AI koppelt die logica aan machine learning: een neurale classifier redeneert binnen logische constraints, een taalmodel wordt gevoed met een kennisgraaf, of je dwingt domeinregels af bij de output. Zo combineer je precisie en transparantie met robuuste patroonherkenning.
Je wint aan consistentie, verminderde hallucinaties, betere datakwaliteit en eenvoudiger compliance, wat handig is in bijvoorbeeld KYC en fraudeonderzoek, klinische besluitvorming, contractanalyse en industriële inspectie. Reken wel op integratiecomplexiteit: je moet regels onderhouden, modellen blijven valideren en conflicten tussen data en logica afhandelen. Begin klein met kernregels en schaal gecontroleerd op.
Machine learning: supervised, unsupervised en reinforcement learning (incl. deep learning)
Bij supervised learning geef je voorbeelden met labels, zodat een model leert om van input naar het juiste antwoord te generaliseren; ideaal voor voorspellen of classificeren als je genoeg gelabelde data hebt. Unsupervised learning zoekt zelf structuur in ruwe data, bijvoorbeeld door te clusteren of anomalieën te detecteren, handig als je patronen wilt ontdekken zonder vooraf gedefinieerde doelen. Reinforcement learning leert door trial-and-error: een agent probeert acties in een omgeving en optimaliseert op basis van beloningen, nuttig voor strategie, logistiek en controleproblemen.
Deep learning is de motor achter veel moderne toepassingen: diepe neurale netwerken herkennen complexe patronen in beeld, spraak en tekst, maar vragen data, rekenkracht en zorgvuldige regulering. In de praktijk combineer je vaak deze vormen, met transfer learning om sneller tot goede resultaten te komen.
[TIP] Tip: Kies supervised voor labels; unsupervised voor patronen; reinforcement voor beslissingen.

Soorten kunstmatige intelligentie naar toepassing
Vanuit de toepassing kun je AI indelen in drie praktische categorieën. Samen dekken ze creëren, voorspellen en autonoom handelen.
- Generatieve AI: creëert nieuwe content (tekst, code, beeld, audio, video) voor contentcreatie, prototyping, documentatie, marketing en automatisering van routinewerk; inclusief copilots, tekst-naar-beeld/-video en spraaksynthese.
- Predictieve en aanbevelingssystemen: schatten wat er waarschijnlijk gebeurt en wat het beste aan te bieden is; toepassingen in vraagvoorspelling, churn- en risico-inschatting, dynamische pricing, voorraadbeheer en personalisatie (recommenders, zoek- en ranking, next-best-action).
- Autonome systemen en robotica: waarnemen, beslissen en handelen zonder constante menselijke sturing; voorbeelden zijn autonome voertuigen en drones, magazijn- en productierobots, inspectie- en servicebots, vaak gestuurd door computer vision, taalmodellen en spraakinterfaces.
In de praktijk worden deze vormen vaak gecombineerd in één oplossing. Kies de categorie die het doel van je project het best dient en voeg waar nodig de juiste sensoren en modellen toe.
Generatieve AI: tekst, beeld, audio en video creëren
Generatieve AI maakt nieuwe content op basis van patronen die het heeft geleerd uit grote datasets. Voor tekst en code zie je grote taalmodellen die zinnen voorspellen en coherente output genereren, terwijl voor beeld en video vaak diffusion-modellen worden gebruikt die stapsgewijs ruis omzetten in een scherp plaatje of clip. In audio kun je stemmen synthetiseren en muziek componeren met text-to-speech en voice cloning. Je stuurt de uitkomst met slimme prompts, voorbeeldstijlen en eventueel fijnslijpen met je eigen data, bijvoorbeeld via lichte fine-tuning.
Let op kwaliteit en risico’s: hallucinaties, bias en mogelijke schending van auteursrechten vragen om controles, watermarking en menselijke review. In de praktijk versnelt generatieve AI creatie, prototyping, personalisatie en documentautomatisering, zolang je duidelijke richtlijnen, veilige data en meetbare evaluatie hanteert.
Predictieve en aanbevelingssystemen
helpen je te voorspellen wat er gaat gebeuren en wat je het best kunt tonen. Predictieve modellen schatten vraag, churn of risico met regressie, classificatie en tijdreeksmodellen. Aanbevelers kiezen items op basis van gedrag en eigenschappen: collaborative filtering (patronen van vergelijkbare gebruikers), content-based (kenmerken van items) en context-aware varianten (tijd, locatie, device). In de praktijk balanceer je exploratie en exploitatie, bijvoorbeeld met banditalgoritmen voor realtime leren.
Pak cold start aan met metadata, embeddings en regels, en bewaak data- en conceptdrift met periodieke retraining. Evalueer niet alleen met metrics als precision@k of RMSE, maar ook met business-impact, diversiteit en fairness. Denk tenslotte aan privacy en consent, en zet logging en A/B-tests in voor continue verbetering.
Autonome systemen en robotica
combineren waarnemen, plannen en sturen in één slimme stack, zodat een voertuig, drone of cobot zelfstandig kan bewegen en taken uitvoeren. Je laat sensoren zoals camera’s, lidar en radar samenwerken via sensorfusie, terwijl SLAM (gelijktijdig lokaliseren en kaartmaken) de omgeving in kaart brengt en de eigen positie bijhoudt. Op basis daarvan plant het systeem veilige paden en past het besturing toe met controllers zoals PID of MPC (modelpredictieve regeling), soms aangevuld met reinforcement learning voor complexe strategieën.
Rekening houden met latency, energieverbruik en randapparatuur maakt edge-compute praktisch onmisbaar. Veiligheid staat centraal: redundantie, fail-safes, geofencing en een mens-in-de-lus voor escalaties. Je versnelt ontwikkeling met simulatie en digital twins, en gebruikt domeinrandomisatie om robuust te blijven bij wisselende omstandigheden, van magazijnvloeren tot drukke stadsstraten.
[TIP] Tip: Koppel bedrijfsdoel aan AI-soort: classificeren, voorspellen, aanbevelen, genereren.

Hoe kies je de juiste vorm voor jouw project
Kies de AI-vorm niet vanuit de hype, maar vanuit je probleem, doelen en randvoorwaarden. Gebruik onderstaande kapstokken om snel tot een passende en haalbare keuze te komen.
- Belangrijke factoren: begin bij duidelijke KPI’s (bv. minder fouten, kortere doorlooptijd, hogere conversie); check je data (hoeveelheid, kwaliteit, labels, rechten/privacy); kies op basis van uitlegbaarheid en controle (symbolische of neuro-symbolische AI) versus prestaties op ongestructureerde data (deep learning of generatieve AI met strakke guardrails); match vorm aan taak (voorspellen/rangschikken = klassiek ML, creëren = generatieve AI, real-time aan de rand = kleine, efficiënte edge-modellen); minimaliseer risico’s en kosten (TCO, bias, compliance, veiligheid) en kies de kleinste oplossing die voldoet-vaak volstaat RAG bovenop een bestaand taalmodel in plaats van finetunen.
- Veelgemaakte fouten die je voorkomt: starten vanuit technologie zonder probleem-fit; data-realiteit onderschatten (kwaliteit, labels, governance); te groot of complex model kiezen; geen heldere evaluatiemetrics of A/B-plan; ontbreken van guardrails en human-in-the-loop; privacy en compliance te laat adresseren; geen productie-strategie (monitoring, drift, retraining); onnodige vendor lock-in.
- Trends om rekening mee te houden: multimodale AI (tekst/beeld/spraak combineren) voor rijkere use-cases; edge AI voor lage latency en privacy-gevoelige scenario’s; kleine taalmodellen (gequantiseerd/gedistilleerd) voor efficiënte inzet on-prem of aan de rand; RAG voor actuele, controleerbare kennisinjectie zonder zwaar finetunen.
Begin klein, test aannames en schaal wat werkt. Zo kies je een oplossing die vandaag waarde levert en meegroeit met je data, eisen en budget.
Belangrijke factoren: data, uitlegbaarheid vs prestaties, risico’s en kosten
Alles begint bij je data: dek je de echte variatie in je domein af, hoe schoon en actueel is het, en heb je toestemming om het te gebruiken? Goede labeling en duidelijke definities voorkomen ruis en bias. Daarna weeg je uitlegbaarheid tegen prestaties af: soms wil je een transparant model met regels of eenvoudige ML, soms is hogere nauwkeurigheid met deep learning de moeite waard, waarbij je post-hoc uitleg en governance nodig hebt.
Beoordeel risico’s zoals discriminatie, datalekken, conceptdrift, veiligheid en naleving van interne en wettelijke eisen, en plan mitigaties als mens-in-de-lus en impactanalyses. Reken tot slot de totale kosten door: ontwikkeling, data-opschoning, infrastructuur, inference, latency, monitoring en onderhoud. Kies de kleinste oplossing die aan je doelen voldoet en houd ruimte om gecontroleerd op te schalen.
Veelgemaakte fouten die je voorkomt
Je voorkomt veel gedoe door niet met een model maar met het probleem te beginnen en meteen duidelijke succescriteria vast te leggen. Veelgemaakte fouten zijn slechte datahygiëne, onduidelijke labels en datalekken in het model (data leakage: info uit de toekomst in je training), geen degelijke baseline en overfitting door te veel finetunen. Ook zie je vaak dat evaluatiemetrics niet aansluiten op je bedrijfsdoelen, dat monitoring ontbreekt en conceptdrift (veranderende patronen) onopgemerkt blijft.
Verder gaat het mis bij privacy en consent, gebrek aan guardrails, geen mens-in-de-lus en nul A/B-tests. Voorkom dit door datakwaliteit te borgen, train/valid/test strikt te scheiden, privacy by design te hanteren, exploitatie en exploratie te balanceren, TCO door te rekenen en eigenaarschap en change management vanaf dag één te regelen.
Trends om rekening mee te houden: multimodale AI, edge AI, kleine taalmodellen en RAG
Multimodale AI begrijpt en combineert tekst, beeld, audio en soms video, zodat je één model kunt gebruiken voor taken als zoeken in documenten met afbeeldingen of visuele kwaliteitscontrole met tekstuitleg. Edge AI draait modellen direct op apparaten zoals camera’s, telefoons of robots, wat latency verlaagt en privacy verbetert doordat data het apparaat niet verlaat. Kleine taalmodellen leveren snelle, betaalbare resultaten op beperkte hardware en zijn met fine-tuning, distillatie en quantization prima aan te passen aan jouw domein.
RAG (Retrieval-Augmented Generation) haalt actuele, betrouwbare context uit je eigen bronnen en laat het model daarop antwoorden, zonder kostbare hertraining. Combineer deze trends slim: multimodaal voor rijke input, edge voor realtime, kleine modellen voor efficiëntie en RAG voor feitelijke juistheid.
Veelgestelde vragen over soorten ai
Wat is het belangrijkste om te weten over soorten ai?
AI kun je indelen naar capaciteiten (ANI, toekomstige AGI, hypothetische ASI), naar werking (symbolisch, neuro-symbolisch, machine learning inclusief deep learning) en naar toepassing (generatief, predictief/aanbevelingen, autonome systemen/robotica). De keuze beïnvloedt prestaties, risico’s en uitlegbaarheid.
Hoe begin je het beste met soorten ai?
Start met een concreet doel en databeoordeling. Kies passende methode (symbolisch, ML, generatief), en bouw een kleine proof-of-concept. Stel succescriteria, privacy/risico-maatregelen en kosten vast. Overweeg edge, kleine taalmodellen of RAG voor efficiëntie.
Wat zijn veelgemaakte fouten bij soorten ai?
Te snel schalen zonder datakwaliteit, governance en MLOps. Blind focussen op deep learning of generatieve modellen terwijl uitlegbaarheid nodig is. Verkeerde metrics, bias en privacy negeren. Vendor lock-in, kosten en onderhoud onderschatten; stakeholders laat betrekken.